When you open up Visual Studio 2013 with the intent of building a new ASP.NET MVC 5 project, you find only one option: an ASP.NET Web Application. This is great, as it represents a moment of clarity in a whirlpool of similar-looking and confusing options. So you click and are presented with various options as to the type of project to create. You want ASP.NET MVC, right? So you pick up the MVC option. What you obtain is a no-op demo application that was probably meant to give you an idea of what it means to code for ASP.NET MVC. Even though the result does nothing, the resulting project is fairly overloaded.
You’ll also find several Nuget packages and assemblies referenced that are not required by the sample application, yet are already there to save time for when you need them in action. This is not a bad idea in theory, as nearly any ASP.NET website ends up using jQuery, Bootstrap, Modernizr, Web Optimization, and others. And if you don’t like it, you still have the option of starting with an empty project and adding MVC scaffolding. This is better, as it delivers a more nimble project even though there are many references that are useless at first. The truth is that any expert developer has his own favorite initial layout of the startup project, including must-have packages and scripts.
Although I may be tempted, I don’t want to push my own ideal project layout on you. My purpose, instead, is applying the Occam’s Razor to the ASP.NET MVC project templates that you get in Visual Studio 2013. I’ll start with the organization of project folders and proceed through startup code, bundling, HTML layout, controllers, layers, HTTP endpoints, and multi-device views. Overall, here are ten good practices for sane ASP.NET MVC 5 development.
#1: Project Folders and Namespaces
Let’s say you used the Visual Studio 2013 project template to create a new project. It works, but it’s rather bloated. Figure 1 shows the list of unnecessary references detected by ReSharper.
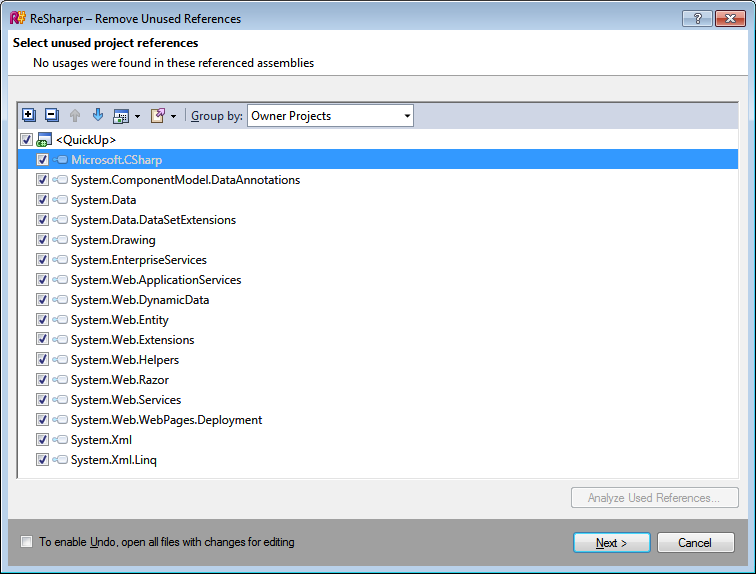
It’s even more interesting to look at the remaining references. Figure 2 shows what you really need to have referenced in order to run a nearly dummy ASP.NET MVC application.

Here’s the minimal collection of Nuget packages you need in ASP.NET MVC.
<packages>
<package id="Microsoft.AspNet.Mvc"
version="5.0.0"
targetFramework="net45" />
<package id="Microsoft.AspNet.Razor"
version="3.0.0"
targetFramework="net45" />
<package id="Microsoft.AspNet.WebPages"
version="3.0.0"
targetFramework="net45" />
</packages>
The project contains the folders listed in Table 1.
When you start adding Nuget packages, some other conventions start appearing such as the Scripts folder for Modernizr and for jQuery and its plugins. You may also find a Content folder for Bootstrap style sheets and a separate Fonts folder for Bootstrap’s glyph icons.
I find such a project structure rather confusing and usually manage to clean it up a little bit. For example, I like to place all content (images, style sheets, scripts, fonts) under the same folder. I also don’t much like the name Models. (I don’t like the name App_Start either but I’ll return to that in a moment.) I sometimes rename Models to ViewModels and give it a structure similar to Views: one subfolder per controller. In really complex sites, I also do something even more sophisticated. The Models folder remains as is, except that two subfolders are addedLInput and View, as shown in Figure 3.
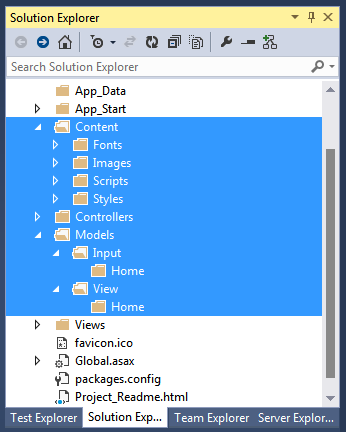
Generally speaking, there are quite a few flavors of models. One is the collection of classes through which controllers receive data. Populated from the model binding layer, these classes are used as input parameters of controller methods. I collectively call them the input model and define them in the Input subfolder. Similarly, classes used to carry data into the Razor views collectively form the view model and are placed under the Models/View folder. Both input and view models are then split on a per-controller basis.
One more thing to note is the matching between project folders and namespaces. In ASP.NET it’s a choice rather than an enforced rule. So you can freely decide to ignore it and still be happy, as I did for years. At some point—but it was several years ago—I realized that maintaining the same structure between namespaces and physical folders was making a lot of things easier. And when I figured out that code assistant tools were making renaming and moving classes as easy as click-and-confirm, well, I turned it into enforcement for any of my successive projects.
#2 Initial Configuration
A lot of Web applications need some initialization code that runs upon startup. This code is usually invoked explicitly from the Application_Start event handler. An interesting convention introduced with ASP.NET MVC 4 is the use of xxxConfig classes. Here’s an example that configures MVC routes:
public class RouteConfig
{
public static void RegisterRoutes(
RouteCollection routes)
{
routes.IgnoreRoute("{resource}.axd/{*pathInfo}");
routes.MapRoute(
name: "Default",
url: "{controller}/{action}/{id}",
defaults: new {
controller = "Home",
action = "Index",
id = UrlParameter.Optional
});
}
}
The code in global_asax looks like this:
RouteConfig.RegisterRoutes(RouteTable.Routes);
For consistency, you can use the same pattern to add your own classes that take care of application-specific initialization tasks. More often than not, initialization tasks populate some ASP.NET MVC internal dictionaries, such as the RouteTable.Routes dictionary of the last snippet (just after the heading for #2).For testability purposes, I highly recommend that xxxConfig methods are publicly callable methods that get system collections injected. As an example, here’s how you can arrange unit tests on MVC routes.
[TestMethod]
public void Test_If_Given_Route_Works()
{
// Arrange
var routes = new RouteCollection();
MvcApplication.RegisterRoutes(routes);
RouteData routeData = null;
// Act & Assert whether the right route was found
var expectedRoute = "{controller}/{action}/{id}";
routeData = GetRouteDataFor("~/product/id/123",
routes); Assert.AreEqual(((Route) routeData.Route).Url,
expectedRoute);}
Note that the code snippet doesn’t include the full details of the code for customGetRouteDataFor method. Anyway, the method uses a mocking framework to mockHttpContextBase and then invokes method GetRouteData on RouteCollectionpassing the mocked context.
var routeData = routes.GetRouteData(httpContextMock);
Many developers just don’t like the underscore convention in the name of some ASP.NET folders, particularly the App_Start folder. Is it safe to rename this folder to something like Config? The answer is: it’s generally safe but it actually depends on what you do in the project.
The possible sore point is the use of the WebActivator Nuget package in the project, either direct or through packages that have dependencies on it. WebActivator is a package specifically created to let other Nuget packages easily add startup and shutdown code to a Web application without making any direct changes to global.asax. WebActivator was created only for the purposes of making Nuget packages seamlessly extend existing Web applications. As WebActivator relies on an App_Start folder, renaming it may cause you some headaches if you extensively add/refresh Nuget packages that depend on WebActivator. Except for this, there are no problems in renaming App_Start to whatever you like most.
#3 Bundling and Minifying CSS Files
Too many requests from a single HTML page may cause significant delays and affect the overall time-to-last-byte metrics for a site. Bundling is therefore the process of grouping distinct resources such as CSS files into a single downloadable resource. In this way, multiple and logically distinct CSS files can be downloaded through a single HTTP request.
Minification, on the other hand, is the process that removes all unnecessary characters from a text-based resource without altering the expected functionality. Minification involves shortening identifiers, renaming functions, removing comments and white-space characters. In general, minification refers to removing everything that’s been added mostly for readability purposes, including long descriptive member names.
Although bundling and minification can be applied together, they remain independent processes. On a production site, there’s usually no reason not to bundle minified CSS and script files. The only exception is for large and very common resources that might be served through a Content Delivery Network (CDN). The jQuery library is a great example.
Bundling requires the Microsoft ASP.NET Web Optimization Framework available as a Nuget package. Downloading the Optimization Framework also adds a few more references to the project. In particular, they are WebGrease and Microsoft Infrastructure. These, in turn, bring their own dependencies for the final graph, shown in Figure 4.

Bundles are created programmatically during the application startup in global.asax. Also in this case, you can use the xxxConfig pattern and add some BundlesConfig class to the App_Startup folder. The BundleConfig class contains at least one method with code very close to the following snippet.
public static void RegisterBundles(
BundleCollection bundles)
{
bundles.Add(new StyleBundle("~/Content/Styles")
.Include("~/Content/Styles/bootstrap.css",
"~/Content/Styles/myapp.css"));
}
The code creates a new bundle object for CSS content and populates it with distinct CSS files defined within the project. Note that the Include method refers to physical paths within the project where the source code to bundle is located. The argument passed to the StyleBundle class constructor instead is the public name of the bundle and the URL through which it will be retrieved from pages. There are quite a few ways to indicate the CSS files to bundle. In addition to listing them explicitly, you can use a wildcard expression:
bundles.Add(new Bundle("~/css")
.Include("~/content/styles/*.css");
Once CSS bundles are defined invoking them is as easy as using the Styles object:
@Styles.Render("~/Bundles/Css")
As you can figure from the last two snippets, ASP.NET optimization extensions come with two flavors of bundle classes: the Bundle class and the StyleBundle class. The former only does bundling; the latter does both bundling and minification. Minification occurs through the services of an additional class. The default CSS minifier class is CssMinify and it is based on some logic packaged in WebGrease. Switching to a different minifier is easy too. All you do is using a different constructor on the StyleBundle class. You use the constructor with two arguments, the second of which is your own implementation of IBundleTransform.
#4 Bundling and Minifying Script Files
Bundling and minification apply to script files in much the same way as bundling and minifying CSS files. The only minor difference is that for frequently used script files (such as jQuery) you might want to use a CDN for even better performance. In operational terms, bundling and minifying script files requires the same process and logic as CSS files. You use the Bundle class if you’re only concerned about packing multiple files together so that they are captured in a single download and cached on the client. Otherwise, if you also want minifying, you use the ScriptBundle class.
bundles.Add(new ScriptBundle("~/Bundles/Core")
.Include(
"~/Content/Scripts/myapp-1.0.0.js",
"~/Content/Scripts/knockout-3.0.0.js")
);
Like StyleBundle, ScriptBundle also features a constructor that accepts an IBundleTransform object as its second argument. This object is expected to bring in some custom logic for minifying script files. The default minifier comes from WebGrease and corresponds to the JsMinify class.
It’s very common today to arrange very complex and graphically rich Web templates that are responsive to changes in the browser’s window size and that update content on the client side through direct access to the local DOM. All this can happen if you have a lot of script files. It’s not, for the most part, JavaScript code that you write yourself. It’s general-purpose JavaScript that forms a framework or a library. In a nutshell, you often end up composing your client-side logic by sewing together multiple pieces, each of which represents a distinct download.
Considering the general recommendation of using as few script endpoints as possible—and bundling does help a lot in that regard—the optimal position of the <script> tags in the body of the HTML page is an open debate. For quite some time, the common practice was to put <script> elements at the end of the document body. This practice was promoted by Yahoo and aimed at avoiding roadblocks during the rendering of the page. By design, in fact, every time the browser encounters a <script> tag, it stops until the script has been downloaded (or recovered from the local cache) and processed.
It’s not mandatory that all script files belong at the bottom. It’s advisable that you distinguish the JavaScript that’s needed for the page to render from the JavaScript that serves other purposes. The second flavor of JavaScript can safely load at the bottom. Well, mostly at the bottom. Consider that as the page renders the user interface in the browser, users may start interacting with it. In doing so, users may trigger events that need some of the other JavaScript placed at the bottom of the page and possibly not yet downloaded and evaluated. If this is your situation, consider keeping input elements that the user can interact with disabled until it’s safe to use them. The ready event of jQuery is an excellent tool to synchronize user interfaces with downloaded scripts. Finally, consider some techniques to load scripts in parallel so that the overall download time becomes the longest of all instead of the sum of all downloads. The simplest way you can do this is through a programmatically created <script> element. You do this using code, as shown below.
var h = document.getElementsByTagName("HEAD")[0];
var script = document.createElement("script");
script.type = "text/javascript";
script.onreadystatechange = function() {...};
script.onload = function() {...};
script.onerror = function() {...};
document.src = "...";
h.appendChild(script)
Script elements are appended to the HEAD element so that parallel download begins as soon as possible. Note that this is the approach that most social Web sites and Google Analytics use internally. The net effect is that all dynamically created elements are processed on different JavaScript threads. This approach is also employed by some popular JavaScript loader frameworks these days.
#5 The Structure of the _Layout File
In ASP.NET MVC, a layout file is what a master page was in classic Web Forms: the blueprint for multiple pages that are ultimately built out of the provided template. What should you have in a master view? And in which order?
With the exceptions and variations mentioned a moment ago for parallelizing the download of multiple scripts, there are two general rules that hold true for the vast majority of websites. The first rule says: Place all of your CSS in the HEAD element. The second rule says: Place all of your script elements right before the closing tag of the <body> element.
There are a few other little things you want to be careful about in the construction of the layout file(s) for your ASP.NET MVC application. First off, you might want to declare explicitly that the document contains HTML5 markup. You achieve this by having the following markup at the very beginning of the layout and subsequently at the beginning of each derived page.
<!DOCTYPE html>
The DOCTYPE instructs older browsers that don’t support specific parts of HTML5 to behave well and correctly interpret the common parts of HTML while ignoring the newest parts. Also, you might want to declare the character set in the HEAD block.
<meta charset="UTF-8">
The charset attribute is case-insensitive, meaning that you can indicate the character set name as UTF-8, utf-8 or otherwise. In general, you don’t use other character sets than UTF-8, as it’s the default encoding for Web documents since HTML4, which came out back in 1999. As far as IIS and ASP.NET are concerned, you have other ways to set the character set. For example, you can type it in the <globalization> section of the web.config file. Having it right in each page just adds clarity. An interesting consequence of clarifying the character set being used is that you can avoid using HTML entities and type special characters directly in the source. Canonical examples are the copyright (©), trademark (®), euro (&euro), dashes (—), and more. The only HTML entities you should use are those that provide the text version of reserved markup characters, such as less-than, greater-than, and ampersand.
Another rather important meta-tag you’ll want to have is the viewport meta-tag whose usage dates back to the early days of smartphones. Most mobile browsers can be assumed to have a rendering area that’s much larger than the physical width of the device. This virtual rendering area is just called the "viewport." The real size of the internal viewport is browser-specific. However, for most smart phones, it’s around 900 pixels. Having such a large viewport allows browsers to host nearly any Web page, leaving users free to pan and zoom to view content, as illustrated inFigure 5.

The viewport meta-tag is a way for you to instruct the browser about the expected size of the viewport.
<meta name="viewport"
content="width=device-width,
initial-scale=1.0,
maximum-scale=1.0,
user-scalable=no" />
In this example, you tell the browser to define a viewport that is the same width as the actual device. Furthermore, you specify that the page isn’t initially zoomed and worse, users can’t zoom in. Setting the width property to the device’s width is fairly common, but you can also indicate an explicit number of pixels.
In ASP.NET MVC, pay a lot of attention to keeping the layout file as thin as possible. This means that you should avoid referencing from the layout file CSS and script files that are referenced by all pages based on the layout. As developers, we certainly find it easier and quicker to reference resources used by most pages right from the layout file. But that only produces extra traffic and extra latency. Taken individually, these extra delays aren’t significant, except that they sum up and may add one or two extra seconds for the page to show and be usable.
In ASP.NET MVC, a layout page consists of sections. A section is an area that derived pages can override. You might want to use this feature to let each page specify CSS and script (and of course markup) that needs be specific. Each layout must contain at least the section for the body.
<div class="container">
@RenderBody()
<hr />
<footer>
© @DateTime.Now.Year - ASP.NET QuickUp
</footer>
</div>
The markup above indicates that the entire body of the page replaces @RenderBody. You can define custom sections in a layout file using the following line:
@RenderSection("CustomScripts")
The name of the section is unique but arbitrary and you can have as many sections as you need with no significant impact on the rendering performance. You just place a @RenderSection call where you want the derived page to inject ad hoc content. The example above indicates a section where you expect the page to insert custom script blocks. However, there’s nothing that enforces a specific type of content in a section. A section may contain any valid HTML markup. If you want to force users to add, say, script blocks, you can proceed as follows:
<script type="text/javascript">
@RenderSection("CustomScripts")
</script>
In this case, overridden sections are expected to contain data that fits in the surrounding markup; otherwise, a parsing error will be raised. In a derived page, you override a section like this:
@section CustomScripts
{
alert("Hello");
}
#6 (Don’t) Use Twitter Bootstrap
Twitter Bootstrap is quickly becoming the de-facto standard in modern Web development, especially now that Visual Studio 2013 incorporates it in the default template for ASP.NET MVC applications. Bootstrap essentially consists of a large collection of CSS classes that are applicable directly to HTML elements and in some cases to special chunks of HTML markup. Bootstrap also brings down a few KBs of script code that extends CSS classes to make changes to the current DOM.
As a matter of fact, with Bootstrap, you can easily arrange the user interface of Web pages to be responsive and provide advanced navigation and graphical features.
The use of Bootstrap is becoming common and, as popularity grows, also controversial. There are reasons to go for it and reasons for staying away from it. My gut feeling is that Bootstrap is just perfect for quick projects where aesthetics are important but not fundamental, and where you need to provide pages that can be decently viewed from different devices with the lowest possible costs. Key arguments in favor of Twitter Bootstrap are its native support for responsive Web design (RWD), deep customizability, and the not-secondary fact that it’s extremely fast to learn and use.
Bootstrap was created as an internal project at Twitter and then open-sourced and shared with the community. When things go this way, there are obvious pros and cons. For Web developers, it’s mostly about good things. Bootstrap offers a taxonomy of elements that you want to have in Web pages today: fluid blocks, navigation bars, breadcrumbs, tabs, accordions, rich buttons, composed input fields, badges and bubbles, lists, glyphs, and more advanced things, such as responsive images and media, auto-completion, and modal dialogs. It’s all there and definable through contracted pieces of HTML and CSS classes. Put another way, when you choose Bootstrap, you choose a higher level markup language than HTML. It’s much the same as when you use jQuery and call it JavaScript. The jQuery library is made of JavaScript but extensively using it raises the abstraction level of JavaScript.
By the same token, using Bootstrap extensively raises the abstraction level of the resulting HTML and makes it look like you’re writing Bootstrap pages instead of HTML pages. This is just great for developer-centric Web solutions. It’s not good for Web designers and for more sophisticated projects where Web designers are deeply involved.
When you choose Bootstrap. you choose a higher-level markup language than HTML. It’s much the same as when you use jQuery and call it JavaScript.
From a Web designer’s perspective, Twitter Bootstrap is just a Twitter solution and even theming it differently is perceived like work that takes little creativity. From a pure Web design perspective, Bootstrap violates accepted (best) practices. In particular, Bootstrap overrides the HTML semantic and subsequently, presentation is no longer separate from the content. Not surprisingly, when you change perspective, the same feature may turn from being a major strength to being a major weakness. Just because Bootstrap overrides the HTML semantic, it tends to favor an all-or-nothing approach. This may be problematic for a Web design team that joins an ongoing project where Bootstrap is being used. In a nutshell, Bootstrap is an architectural decision—and one that’s hard to change on the go. So, yes, it makes presentation tightly bound to content. Whether this is really an issue for you can’t be determined from the outside of the project.
Last but not least, the size of Twitter Bootstrap is an issue. Minified, it counts for about 100K of CSS, 29K of JavaScript plus fonts. You can cut this short by picking exactly the items you need. The size is not an issue for sites aimed at powerful devices such as a PC, but Bootstrap for sites aimed at mobile devices may be a bit too much. If you’re going to treat desktop devices differently from mobile devices, you might want to look into the mobile-only version of Bootstrap that you find at .
#7 Keep Controllers Thin
ASP.NET MVC is often demonstrated in the context of CRUD applications. CRUD is a very common typology for applications and it’s a very simple typology indeed. For CRUD applications, a fat controller that serves any request directly is sometimes acceptable. When you combine the controller with a repository class for each specific resource you handle, you get good layering and achieve nifty separation of concerns.
It’s essential to note that the Model-View-Controller pattern alone is not a guarantee of clean code and neatly separated layers. The controller simply ensures that any requests are routed to a specific method that’s responsible for creating the conditions for the response to be generated and returned. In itself, an action method on a controller class is the same as a postback event handler in old-fashioned Web Forms applications. It’s more than OK to keep the controller action method tightly coupled to the surrounding HTTP context and access it from within the controller method intrinsic objects such as Session, Server, and Request. A critical design goal is keeping the controller methods as thin as possible. In this way, the controller action methods implement nearly no logic or very simple workflows (hardly more than one IF or two) and there’s no need to test them.
As each controller method is usually invoked in return to a user’s gesture, there’s some action to be performed. Which part of your code is responsible for that? In general, a user action triggers a possibly complex workflow. It’s only in a basic CRUD, like the very basic Music Store tutorial, that workflow subsequent to user actions consists of one database access that the resource repository carries out. You should consider having an intermediate layer between controllers and repositories. (See Figure 6.)

The extra layer is the application layer and it consists of classes that typically map to controllers. For example, if you have HomeController, you might also want to have some HomeService class. Each action in HomeController ends up calling one specific method in HomeService. Listing 1 shows some minimalistic code to illustrate the pattern.
The Index method invokes the associated worker service to execute any logic. The service returns a view model object that is passed down to the view engine for the actual rendering of the selected Razor view. Figure 7 shows instead a modified project structure that reflects worker services and the application layer of the ASP.NET MVC application.

#8 Membership and Identity
To authenticate a user, you need some sort of a membership system that supplies methods to manage the account of a user. Building a membership system means writing the software and the related user interface to create a new account and update or delete existing accounts. It also means writing the software for editing any information associated with an account. Over the years, ASP.NET has offered a few different membership systems.
Historically, the first and still largely used membership system is centered on the Membership static class. The class doesn’t directly contain any logic for any of the methods it exposes. The actual logic for creating and editing accounts is supplied by a provider component that manages an internal data store. You select the membership in the configuration file. ASP.NET comes with a couple of predefined providers that use SQL Server or Active Directory as the persistence layer. Using predefined providers is fine, as it binds you to a predefined storage schema and doesn’t allow any reuse of existing membership tables. For this reason, it’s not unusual that you end up creating your own membership provider.
Defining a custom membership provider is not difficult at all. All you do is derive a new class from MembershipProvider and override all abstract methods. At a minimum, you override a few methods such as ValidateUser, GetUser, CreateUser, and ChangePassword. This is where things usually get a bit annoying.
The original interface of the Membership API is way too complicated with too many methods and too many quirks. People demanded a far simpler membership system. Microsoft first provided the SimpleMembership provider and with Visual Studio 2013, what appears to be the definitive solution: ASP.NET Identity.
In the ASP.NET Identity framework, all of the work is coordinated by the authentication manager. It takes the form of the UserManager<T> class, which basically provides a façade for signing users in and out.
public class UserManager<T> where T : IUser
{
:
}
The type T identifies the account class to be managed. The IUser interface contains a very minimal definition of the user, limited to ID and name. The ASP.NET Identity API provides the predefined IdentityUser type that implements the IUser interface and adds a few extra properties such as PasswordHash and Roles. In custom applications, you typically derive your own user type inheriting from IdentityUser. It’s important to notice that getting a new class is not required; you can happily work with native IdentityUser if you find its structure appropriate.
User data storage happens via the UserStore<T> class. The user store class implements the IUserStore interface that summarizes the actions allowed on the user store:
public interface IUserStore<T> : where T:IUser
{
Task CreateAsync(T user);
Task DeleteAsync(T user);
Task<T> FindByIdAsync(string userId);
Task<T> FindByNameAsync(string userName);
Task UpdateAsync(T user);
}
As you can see, the user store interface looks a lot like a canonical repository interface, much like those you might build around a data access layer. The entire infrastructure is glued together in the account controller class. The skeleton of an ASP.NET MVC account controller class that is fully based on the ASP.NET Identity API is shown in Listing 2.
The controller holds a reference to the authentication identity manager. An instance of the authentication identity manager is injected in the controller. The link between the user store and the data store is established in the ApplicationDbContext class. You’ll find this class defined by the ASP.NET MVC 5 wizard if you enable authentication in the Visual Studio 2013 project template.
public class ApplicationDbContext :
IdentityDbContext<IdentityUser>
{
public ApplicationDbContext() :
base("DefaultConnection")
{
}
}
The base IdentityDbContextclass inherits from DbContextand is dependent on Entity Framework. The class refers to an entry in the web.config file, where the actual connection string is read. The use of Entity Framework Code First makes the structure of the database a secondary point. You still need a well-known database structure, but you can have the code to create one based on existing classes instead of manual creation in SQL Server Management Studio. In addition, you can use Entity Framework Code First Migration tools to modify a previously created database as you make changes to the classes behind it.
Currently, ASP.NET Identity covers only the basic features of membership but its evolution is not bound to the core ASP.NET Framework. Features that the official interfaces don’t cover yet (such as enumerating users) must be coded manually, which brings you back to the handcrafted implementation of membership.
#9 Expose HTTP Endpoints
An architecture for Web applications that’s becoming increasingly popular is having a single set of HTTP endpoints—collectively known as Web services—consumed by all possible clients. Especially if you have multiple clients (like mobile applications and various Web frontends) a layer of HTTP endpoints is quite helpful to have. Even if you only have a single client frontend, a layer of HTTP endpoints is helpful as it allows you to have a bunch of Ajax-based functionalities integrated in HTML pages. The question is: How would you define such endpoints?
If you need an API—or even a simple set of HTTP endpoints—exposed out of anything but ASP.NET MVC (such as Web Forms or Windows services) using Web API is a no-brainer. But if all you have is an ASP.NET MVC application, and are tied to IIS anyway, you can simply use a separate ASP.NET MVC controller and make it return JSON.
There are many posts out there calling for a logical difference between Web API controllers and ASP.NET MVC controllers. There’s no doubt that a difference exists because overall Web API and ASP.NET MVC have different purposes. Anyway, the difference becomes quite thin and transparent when you consider it from the perspective of an ASP.NET MVC application.
With plain ASP.NET MVC, you can easily build an HTTP façade without learning new things. In ASP.NET MVC, the same controller class can serve JSON data or an HTML view. However, you can easily keep controllers that return HTML separate from controllers that only return data. A common practice consists in having an ApiController class in the project that exposes all endpoints expected to return data. In Web API, you have a system-provided ApiController class at the top of the hierarchy for controllers. From a practical perspective, the difference between ASP.NET MVC controllers and Web API controllers hosted within the same ASP.NET MVC is nearly non-existent. At the same time, as a developer, it’s essential that you reason about having some HTTP endpoints exposed in some way.
Web API and ASP.NET MVC have different purposes.
#10 Use Display Modes
One of the best-selling points of CSS is that it enables designers and developers to keep presentation and content neatly separated. Once the HTML skeleton is provided, the application of different CSS style sheets can produce even radically different results and views. With CSS, you can only hide, resize, and reflow elements. You can’t create new elements and you can add any new logic for new use-cases.
In ASP.NET MVC, a display mode is logically the same as a style sheet except that it deals with HTML views instead of CSS styles. A display mode is a query expression that selects a specific view for a given controller action. In much the same way, the Web browser on the client processes CSS media query expressions and applies the appropriate style sheet; a display mode in server-side ASP.NET MVC processes a context condition and selects the appropriate HTML view for a given controller action.
Display modes are extremely useful in any scenario where multiple views for the same action can be selected based on run-time conditions. The most compelling scenario, however, is associated with server-side device detection and view routing. By default, starting with ASP.NET MVC 4, any Razor view can be associated with a mobile-specific view. The default controller action invoker automatically picks up the mobile-specific view if the user agent of the current request is recognized as the user agent of a mobile device. This means that if you have a pair of Razor views such as index.cshtml and index.mobile.cshtml, the latter will be automatically selected and displayed in lieu of the former if the requesting device is a mobile device. This behavior occurs out of the box and leverages display modes. Display modes can be customized to a large extent. Here’s an example:
var tablet = new DefaultDisplayMode("tablet")
{
ContextCondition = (c => IsTablet(c.Request))
};
var desktop = new DefaultDisplayMode("desktop")
{
ContextCondition = (c => return true)
};
displayModes.Clear();
displayModes.Add(tablet);
displayModes.Add(desktop);
The preceding code goes in the Application_Start event of global.asax and clears default existing display modes and then adds a couple of user-defined modes. A display mode is associated with a suffix and a context condition. Display modes are evaluated in the order in which they’re added until a match is found. If a match is found—that is, if the context condition holds true—then the suffix is used to complete the name of the view selected. For example, if the user agent identifies a tablet, then index.cshtml becomes index.tablet.cshtml. If no such Razor file exists, the view engine falls back to index.cshtml.
Display modes are an extremely powerful rendering mechanism but all this power fades without a strong mechanism to do good device detection on the server side. ASP.NET lacks such a mechanism. ASP.NET barely contains a method in the folds of the HttpRequest object to detect whether a given device is mobile or not. The method is not known to be reliable and work with just any old device out there. It lacks the ability to distinguish between smartphones, tablets, Google glasses, smart TVs, and legacy cell phones. Whether it works in your case is up to you.
If you’re looking for a really reliable device detection mechanism, I recommend WURFL, which comes through a handy Nuget package. For more information on WURFL, you can check out my article that appeared in the July 2013 issue of CODE Magazine, available at the following URL: .
Display modes are extremely useful in any scenario where multiple views for the same action can be selected based on run time conditions.
Summary
ASP.NET MVC 5 is the latest version of Microsoft’s popular flavor of the ASP.NET platform. It doesn’t come with a full bag of new goodies for developers but it remains a powerful platform for Web applications. ASP.NET is continuously catching up with trends and developments in the Web space and writing a successful ASP.NET MVC application is a moving target. This article presented ten common practices to build ASP.NET MVC applications with comfort and ease.
Listing 1: A layered controller class
public interface IHomeService
{
IndexViewModel GetModelForIndex();
}
public class HomeController : Controller
{
private readonly IHomeService _service;
public HomeController() : this (new HomeService())
{
}
public HomeController(IHomeService service)
{
_service = service;
}
public ActionResult Index()
{
var model = _service.GetModelForIndex();
return View(model);
}
}
public class ViewModelBase
{
public String Title { get; set; }
}
public class IndexViewModel : ViewModelBase
{
// More members here
}
Listing 2. Sample account controller class
public class AccountController : Controller
{
public UserManager<IdentityUser> UserManager { get; set; }
public AccountController(UserManager<IdentityUser> manager)
{
UserManager = manager;
}
public AccountController() : this(
new UserManager<IdentityUser>(
new UserStore<IdentityUser>(new ApplicationDbContext())))
{
}
// Other members here
}
Table 1: Typical project folders.
| Folder name | Intended goal |
| App_Data | Contains data used by the application, such as proprietary files (e.g., XML files) or local databases |
| App_Start | Contains initialization code. By default, it simply stores static classes invoked from within global.asax. |
| Controllers | Folder conventionally expected to group all controllers used by the application |
| Models | Folder conventionally expected to contain classes representing the rather nebulous MVC concept of "model" |
| Views | Folder conventionally expected to group all Razor views used by the application. The folder is articulated in subfolders,one per controller |



No comments:
Post a Comment